
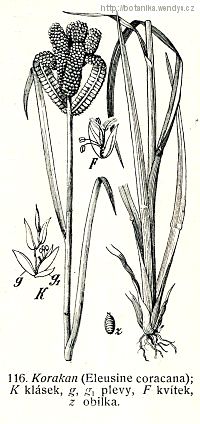
 Finger millet (Eleusine coracana) is the second of the four millets to be described in this series of posts, and the fourth most produced among them worldwide. It is a native of the highlands of the Horn …
Finger millet (Eleusine coracana) is the second of the four millets to be described in this series of posts, and the fourth most produced among them worldwide. It is a native of the highlands of the Horn …
All posts by Don
Four millets: 1. Pearl millet, or bajri
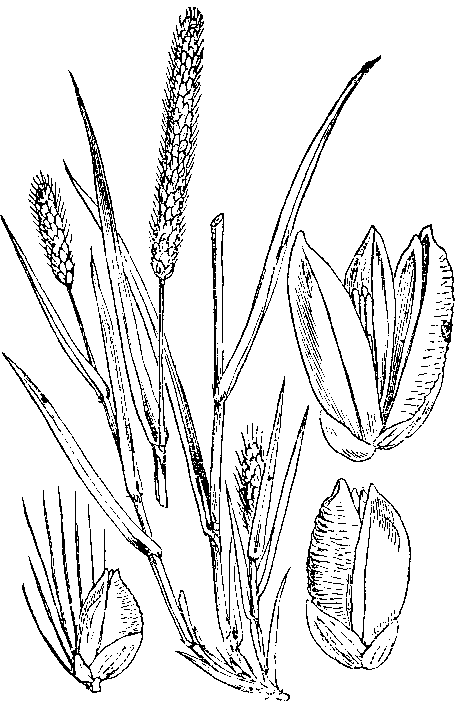 Pearl millet (Pennisetum glaucum) is the first if the four millets to be described in this series of posts. It is the most widely cultivated of the millets and the sixth most important grain worldwide. Being primarily …
Pearl millet (Pennisetum glaucum) is the first if the four millets to be described in this series of posts. It is the most widely cultivated of the millets and the sixth most important grain worldwide. Being primarily …
Four millets: Recognizing the differences
“Millet” can actually refer to any one of several related but distinct kinds of grains, though you wouldn’t know it seeing the term in lists of ingredients, statistics on crop production and trade, or some articles about food …
Return of Multidisciplinary Perspectives
After a long hiatus, I am resuming this blog. The reasons for leaving off had to do with a combination of factors – other priorities and technical issues related to falling behind on updating the WordPress.org software.
Updating a really …
CFP: Language and Development 2015
The biennial Language and Development Conference will next be held in New Delhi, India on 18-20 November 2015. The first page of the call for papers is displayed below – note 26 June deadline extended to July 12. For …
Reviving this blog
I briefly restarted this blog on the donosborn.wordpress.com site that I had reserved in 2008 but not used since then. This was the first post on that site, which now serves as a mirror for the blog. This post is …